6. Classification
Supervised classification
In supervised classification (in contrast to unsupervised classification) reference classes are used as additional information. This process safely determines which classes are the result of the classification. The following steps are the most common:
- Definition of the land use and land cover classes (spectral classes such as coniferous forest, deciduous forest, water, agriculture etc.)
- Classification of suitable training areas (reference areas for each class)
- Execution of the true classification with the help of a suitable classification algorithm
- Verification, evaluation, and inspection of the results.

Training Areas
The statistic classification for so called training areas is "trained". The areas are selected from the examined area (for example from maps or air images) and mapped in a site exploration. The exemplary regions for each class will be defined (for example land use classes such as coniferous forest, water areas, etc.) and will be made available as a reference for the classifier.
Maximum likelihood classification
The real classification of the satellite images takes places with the help of extensive classification algorithms, such as for example maximum likelihood, minimum distance, cubic procedures (parallelepiped), or hierarchical classification.
The most common is the maximum likelihood classification. It touches a probability density function, meaning, the classifier guesses the probability with which a specific pixel belongs to a specific class. Larger deviations from the center point will be allowed where a pixel is not in the area of a contesting category - less where such a competition exists.
Task: How should the stars (red and turquoise) be classified here?
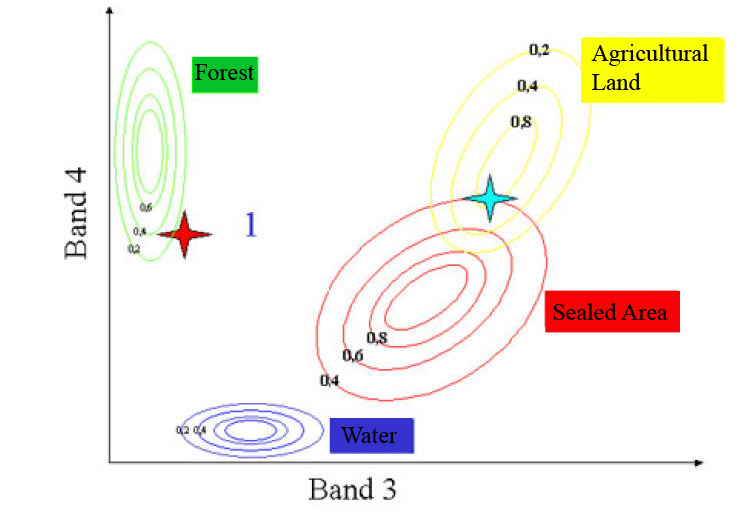
Source: Naumann 2008
Evaluation and inspection of the results
To verify/inspect the results, the probability of a pixel belonging to a class and the difference between the probabilities that it belongs to the next class and the suspected class will be calculated. The results will be provided in the form of a confusion matrix of the training area, in order to show the suitability of the training area.
