1. Modèles empiriques de régression linéaire
Vous disposez de données expérimentales extraites du fichier de données et représentées dans la figure ci-dessous. Accédez au fichier de données et importez-le dans un tableur, afin de produire un graphe comme celui montré ci-dessous, mais sans les droites de régression linéaire bleue et rouge.
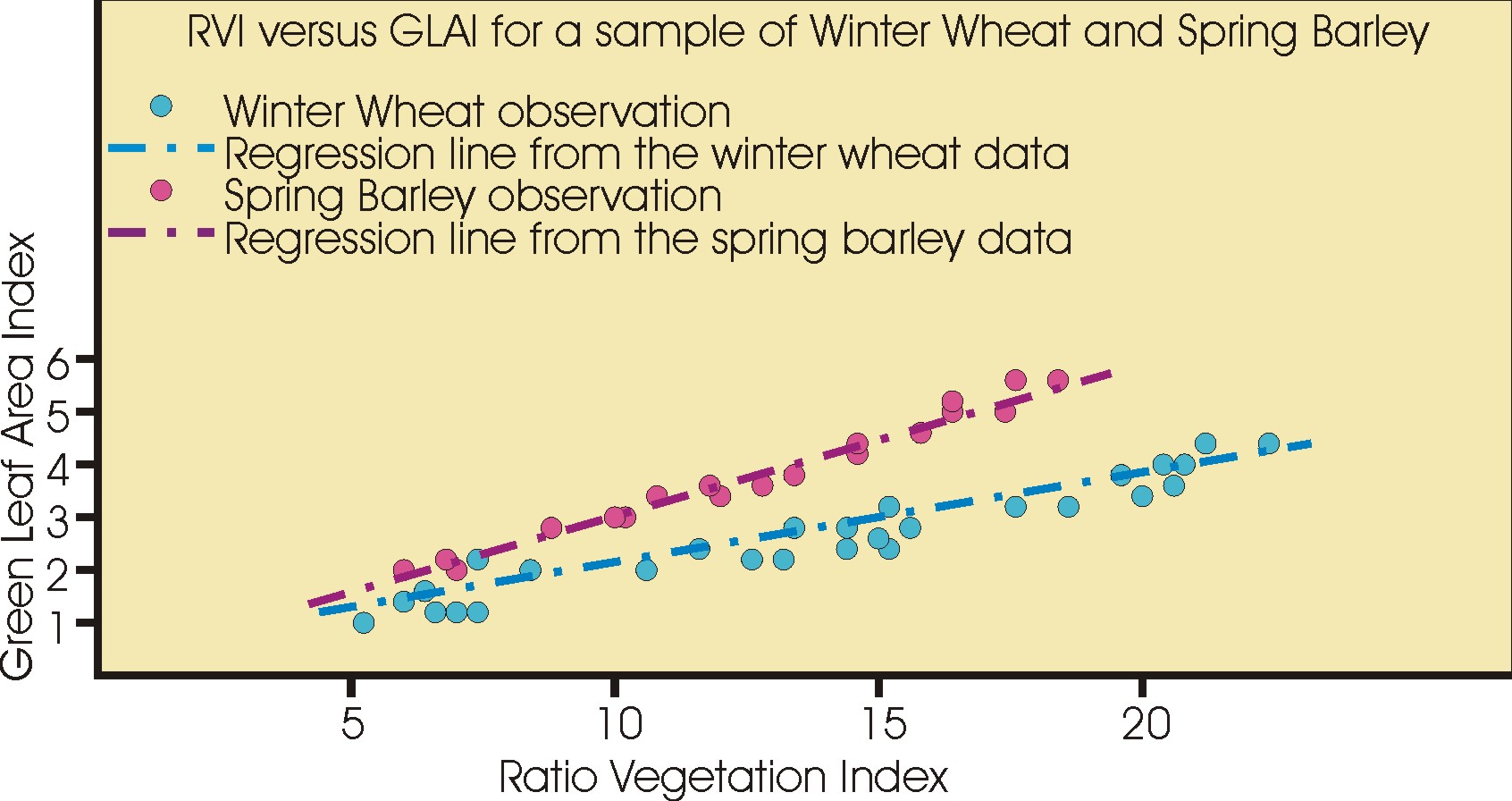
Vous pouvez voir que les données sont hautement corrélées, qu'elles ne se situent pas exactement sur une droite, mais qu'une droite semble être une représentation raisonnable des données. Vous avez ainsi simplement examiné les données. Comme ces données se répartissent presque sur une droite, nous allons utiliser un modèle de régression linéaire pour estimer l'indice foliaire (Green Leaf Area Index - GLAI), la variable dépendante y, grâce aux données de l'indice de végétation de type rapport (Ratio Vegetation Index - RVI), et la variable indépendante x, en utilisant les données expérimentales pour construire le modèle.
Un modèle linéaire a la forme
Où b0 est la constante (offset), correspondant à un décalage constant de la variable dépendante le long de l'axe y, et b1 est le coefficient de x (gain), correspondant à la mise à l'échelle des variations des deux variables.
Il y a deux inconnues dans cette équation, le coefficient de x et la constante, nous pouvons donc la résoudre si nous disposons de deux valeurs du RVI et des valeurs équivalentes pour le GLAI.

Mais nous disposons de beaucoup plus d'observations que ça dans le fichier de données, 53 observations pour l'orge de printemps et 62 pour le blé d'hiver. En plus de cela, les données ne se répartissent pas exactement sur une ligne droite, donc pour chaque valeur observée de la variable indépendante x (RVI), la variable dépendante y (GLAI) a une faible probabilité de se situer exactement sur la droite, mais bien plus ou moins éloignée de celle-ci d'une petite distance. Cette distance, mesurée parallèlement à l'axe y, est appelée le résidu, et est représentée par le symbole ε dans l'équation.
Nous devons trouver un moyen d'obtenir les valeurs du coefficient de x et de la constante correspondant à la droite s'ajustant le mieux possible aux données en fonction de quelques critères. Le critère habituel est que la somme des carrés des résidus soit minimale. Ceci revient à dire que nous voulons trouver la droite qui s'ajuste aux données avec la plus petite variance possible dans la direction de l'axe y. La méthode que nous utilisons dans ce but est appelée la méthode des moindres carrés, et vous verrez cette méthode en détail dans la leçon suivante.
Exercices
- Accédez au fichier de données que vous importez dans un tableur, pour obtenir quatre colonnes de données, le RVI et le GLAI pour le blé d'hiver et l'orge de printemps. Construisez un diagramme de dispersion des couples de valeurs (x,y) correspondant aux deux types de cultures symbolisées par une couleur différente.
- 2. Calculez la moyenne et la variance pour chaque colonne de données, et trouvez la corrélation entre les deux variables pour le blé d'hiver et l'orge de printemps.
